SeimiCrawler一个敏捷强大的Java爬虫框架
An agile,powerful,standalone,distributed crawler framework.
SeimiCrawler的目标是成为Java世界最好用最实用的爬虫框架。
1.简介
SeimiCrawler是一个敏捷的,独立部署的,支持分布式的Java爬虫框架,希望能在最大程度上降低新手开发一个可用性高且性能不差的爬虫系统的门槛,以及提升开发爬虫系统的开发效率。在SeimiCrawler的世界里,绝大多数人只需关心去写抓取的业务逻辑就够了,其余的Seimi帮你搞定。设计思想上SeimiCrawler受Python的爬虫框架Scrapy启发,同时融合了Java语言本身特点与Spring的特性,并希望在国内更方便且普遍的使用更有效率的XPath解析HTML,所以SeimiCrawler默认的HTML解析器是JsoupXpath(独立扩展项目,非jsoup自带),默认解析提取HTML数据工作均使用XPath来完成(当然,数据处理亦可以自行选择其他解析器)。并结合SeimiAgent彻底完美解决复杂动态页面渲染抓取问题。完美支持SpringBoot,让你的想象力与创造力发挥到极致。
2.需要
JDK1.8+
3.快速开始
3.1.maven依赖
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>参考github最新版本</version>
</dependency>
3.2.在SpringBoot中
创建一个标准的SpringBoot工程,在包crawlers下添加爬虫规则,例如:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
//两个是测试去重的
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response){
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
//do something
} catch (Exception e) {
e.printStackTrace();
}
}
}
application.properties中配置
#启动SeimiCrawler
seimi.crawler.enabled=true
seimi.crawler.names=basic
标准的springBoot启动
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}
更复杂的用法可以参考下面更为详细的文档或是参考Github中的demo。
3.3.常规用法
创建一个普通的Maven工程,在包crawlers下添加爬虫规则,例如:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
//两个是测试去重的
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response){
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
//do something
} catch (Exception e) {
e.printStackTrace();
}
}
}
然后随便某个包下添加启动Main函数,启动SeimiCrawler:
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("basic");
}
}
以上便是一个最简单的爬虫系统开发流程。
4.原理
4.1.基本原理
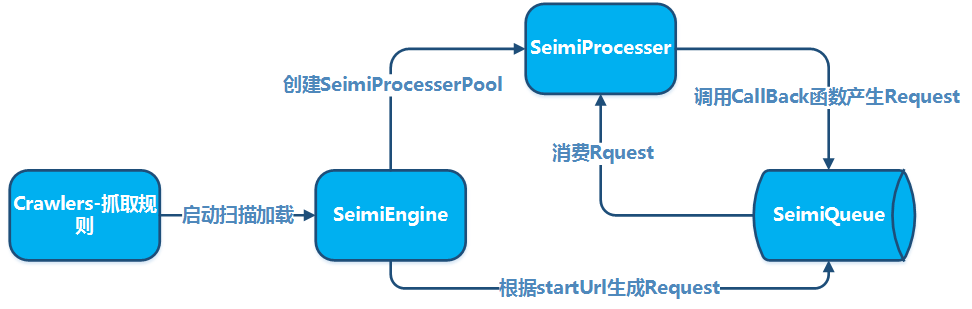
4.2.集群原理
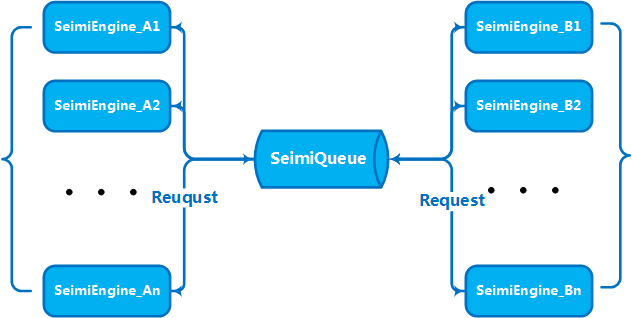
5.如何开发
5.1.约定
之所以要有一些约定,主要目的是让使用SeimiCrawler开发的爬虫系统的源码更加的规范可读,大家都遵守一个约定,那么在团队成员相互协作开发的过程中,业务工程的代码在团队成员间就会更加的易读,易改。不至于某人开发了一个业务逻辑,另一个接手的人连到哪里去找他的类都很困难,这不是我们要的。我们要强大,简单,好用。最后,有约定不代表SeimiCrawler不够灵活。
- 由于SeimiCrawler的context基于spring实现,所以支持几乎所有spring格式的配置文件和spring通常用法。SeimiCrawler会扫描工程classpath下所有xml格式配置文件,但是只有文件名以
seimi开头的xml配置文件能被SeimiCrawler识别并加载。 - SeimiCrawler的日志使用slf4j,可自行配置具体的实现。
- Seimi开发时要注意的约定,会在下面的开发要点中一一介绍。
5.2.第一个爬虫规则类-crawler
爬虫规则类是使用SeimiCrawler开发爬虫最核心的部分,快速开始中的Basic类就是一个基本的爬虫类。写一个crawler需注意一下几点:
- 需继承BaseSeimiCrawler
- 需打上@Crawler注解,注解中name属性是可有可无的,如果设置了,那么这个crawler则以你定义的名字命名,否则默认使用你创建的类名。
- 所有想要被SeimiCrawler扫描到的crawler需放在crawlers包下,如:cn.wanghaomiao.xxx.crawlers,也可以参考项目附带的demo工程。
初始化好Crawler后,你需要实现两个最基本的方法public String[] startUrls();和public void start(Response response),实现后一个简单的爬虫就算写完了。
5.2.1.注解@Crawler
目前@Crawler注解有下面几个属性:
- name 自定义一个爬虫规则的名字,一个SeimiCrawler可扫描范围内的工程中不能有同名的。默认使用类名。
- proxy 告诉Seimi这个爬虫是否使用代理,以及使用什么样的代理。目前支持三种格式http|https|socket://host:port,这一版还没支持带用户名和密码的代理。
- useCookie 是否启用cookies,启用后即可像浏览器一样保持你的请求状态,同样的也会被追踪。
- queue 指定当前这个爬虫要使用的数据队列,默认的是本地队列实现DefaultLocalQueue.class,也可以配置使用默认的redis版实现或是自行基于其他队列系统的实现,这个后面会进行更为详细的介绍。
- delay 设置请求抓取的时间间隔单位为秒,默认为0即没有间隔。
- httpType Downloader实现类型,默认的Downloader实现为Apache Httpclient,可以通过他将网络请求处理实现改为OkHttp3。
- httpTimeOut 支持自定义超时间,单位毫秒,默认15000ms
5.2.2.实现startUrls()
这是爬虫的入口,返回值为URL的数组。默认startURL会被以GET请求处理,如果某些特殊情况下你需要让Seimi以POST方法处理你的startURL,你只需在这条URL的后面加上##post即可,例如http://passport.cnblogs.com/user/signin?ReturnUrl=http%3a%2f%2fi.cnblogs.com%2f##post,这个指定不区分大小写。这个规则仅适用startURL的处理。
5.2.3.实现start(Response response)
这个方法是针对startURL的回调函数,即告诉Seimi如何处理请求startURL返回的数据。
5.2.4.Response数据提取
- 文本类结果
Seimi默认推荐使用XPath来提取HTML数据,虽然初期学习了解XPath有一点点的学习成本,但是与在你了解他之后给你带来的开发效率相比较来说实在是太微不足道了。
JXDocument doc = response.document();即可拿到JXDocument(JsoupXpath的文档对象),然后就可以通过doc.sel("xpath")提取任何你想要的数据了,提取任何数据应该都是一条XPath语句就能搞定了。对Seimi使用的XPath语法解析器以及想对XPath进一步了解的同学请移步JsoupXpath。当然,实在对XPath提不起感觉的话,那么response里有原声的请求结果数据,您可自行选择其他数据解析器进行处理。 - 文件类结果
如果是文件类的返回结果,可以使用
reponse.saveTo(File targetFile)进行存储,或是获取文件字节流byte[] getData()进行其他操作。
5.2.4.1.内部属性一览
private BodyType bodyType;
private Request request;
private String charset;
private String referer;
private byte[] data;
private String content;
/**
* 这个主要用于存储上游传递的一些自定义数据
*/
private Map<String, String> meta;
private String url;
private Map<String, String> params;
/**
* 网页内容真实源地址
*/
private String realUrl;
/**
* 此次请求结果的http处理器类型
*/
private SeimiHttpType seimiHttpType;
5.2.5.回调函数
使用默认的一个回调函数显然是不能满足你的要求的,如果你还想把startURL页面中的某些URL提取出来再进行请求获取数据并进行处理的话,你就需要自定义回调函数了。注意点如下:
- V2.0开始支持方法引用,设置回调函数更加自然,如:Basic::getTitle。
- 在回调函数里的产生的Request可以指定其他回调函数也可以指定自己为回调函数。
- 作为回调函数需满足这个格式:public void callbackName(Response response),即方法是公有的,有且只能有一个参数Response,没有返回值。
- Request设置一个回调函数只需提供这个回调函数的String类型的名称即可,如:快速开始中那个getTitle。
- 继承了BaseSeimiCrawler的Crawler可以在回调函数内直接调用父类的push(Request request)将新的抓取请求发送掉请求队列。
- 可以通过Request.build()创建Request。
5.2.6.Request内部一览
public class Request {
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta);
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta,int maxReqcount);
public static Request build(String url, String callBack);
public static Request build(String url, String callBack, int maxReqCount);
@NotNull
private String crawlerName;
/**
* 需要请求的url
*/
@NotNull
private String url;
/**
* 要请求的方法类型 get,post,put...
*/
private HttpMethod httpMethod;
/**
* 如果请求需要参数,那么将参数放在这里
*/
private Map<String,String> params;
/**
* 这个主要用于存储向下级回调函数传递的一些自定义数据
*/
private Map<String,Object> meta;
/**
* 回调函数方法名
*/
@NotNull
private String callBack;
/**
* 回调函数是否为Lambda表达式
*/
private transient boolean lambdaCb = false;
/**
* 回调函数
*/
private transient SeimiCallbackFunc callBackFunc;
/**
* 是否停止的信号,收到该信号的处理线程会退出
*/
private boolean stop = false;
/**
* 最大可被重新请求次数
*/
private int maxReqCount = 3;
/**
* 用来记录当前请求被执行过的次数
*/
private int currentReqCount = 0;
/**
* 用来指定一个请求是否要经过去重机制
*/
private boolean skipDuplicateFilter = false;
/**
* 针对该请求是否启用SeimiAgent
*/
private boolean useSeimiAgent = false;
/**
* 自定义Http请求协议头
*/
private Map<String,String> header;
/**
* 定义SeimiAgent的渲染时间,单位毫秒
*/
private long seimiAgentRenderTime = 0;
/**
* 用于支持在SeimiAgent上执行指定的js脚本
*/
private String seimiAgentScript;
/**
* 指定提交到SeimiAgent的请求是否使用cookie
*/
private Boolean seimiAgentUseCookie;
/**
* 告诉SeimiAgent将结果渲染成何种格式返回,默认HTML
*/
private SeimiAgentContentType seimiAgentContentType = SeimiAgentContentType.HTML;
/**
* 支持添加自定义cookie
*/
private List<SeimiCookie> seimiCookies;
/**
* 添加json request body支持
*/
private String jsonBody;
}
5.2.7.自定义UserAgent(可选)
SeimiCrawler的默认UA为SeimiCrawler/JsoupXpath,如果想自定义UserAgent可以覆盖BaseSeimiCrawler的public String getUserAgent(),每次处理请求时SeimiCrawler都会获取一次UserAgent,所以如果你想伪装UserAgent的话可以自行实现一个UA库,每次随机返回一个。
5.2.8.启用cookies(可选)
在介绍@Crawler注解时已经对其介绍过了,这里再次强调主要是方便快速浏览这些基本功能,是否启用cookies是通过@Crawler注解中的useCookie属性来进行配置。另外还可以通过Request.setSeimiCookies(List<SeimiCookie> seimiCookies)或是Request.setHeader(Map<String, String> header)来进行自定义设置,Request中可以做很多自定义的东西,大家可以看下Request对象,对他更加熟悉下,可能会打开你很多思路。
5.2.9.启用proxy(可选)
通过@Crawler注解中的proxy属性来进行配置,具体请参考@Crawler的介绍,如果希望能动态的指定proxy,请移步下文"设置动态代理"。目前支持三种格式http|https|socket://host:port。
5.2.10.设置delay(可选)*
通过@Crawler注解中的delay属性来进行配置,设置请求抓取的时间间隔单位为秒,默认为0即没有间隔。在很多情况下内容方都会把请求频率的限制作为反爬虫的一种手段,所以需要的情况可以自行调整添加这个参数来实现更好的抓取效果。
5.2.11.设置请求URL白名单匹配规则
通过override BaseSeimiCrawler的public String[] allowRules()来设置URL请求白名单规则,规则为正则表达式,匹配到任意一条即放行。
5.2.12.设置请求URL黑名单匹配规则
通过override BaseSeimiCrawler的public String[] denyRules()来设置URL请求黑名单规则,规则为正则表达式,匹配到任意一条即阻止请求。
5.2.13.设置动态代理
通过override BaseSeimiCrawler的public String proxy()来告诉Seimi某一次请求使用哪个代理地址,这里可以自行从已有代理库用顺序或是随机返回一个代理地址。且只要这个代理地址非空,那么在@Crawler中proxy属性设置则失效。目前支持三种格式http|https|socket://host:port。
5.2.14.是否开启系统去重
通过@Crawler注解中的useUnrepeated属性来控制是否开启系统去重,默认开启
5.2.15.关于自动跳转
目前SeimiCrawler支持301、302以及meta refresh跳转,对于这类跳转URL,可以通过Response对象的getRealUrl()获取内容对应重定向或是跳转后的真实连接
5.2.16.异常请求处理
一个请求如何处理时出现异常,他会三次机会被重新放回到处理队列中进行在处理,但是如果最后还是失败了的话,那么系统将调用 crawler的public void handleErrorRequest(Request request)方法去处理这个有问题的请求,默认的实现是用日志记录,当然开发者可以自行override这个方法添加自己处理实现。
5.2.17.SeimiAgent支持
这个得重点的介绍一下了,对SeimiAgent还不是很了解的同学可以先看看SeimiAgent项目主页,简单的说,SeimiAgent是一个运行于服务器端的浏览器内核,它是基于QtWebkit开发,并以标准的http接口对外提供服务,专门用来解决复杂动态网页的渲染,截取快照,监控等需求。总之他对页面的处理是标准浏览器级的,你可以基于他拿到任何浏览器上可以拿到的信息。
5.2.17.1.基本配置
为了让seimiCrawler支持SeimiAgent,首先得告诉SeimiAgent的服务地址。
5.2.17.1.1.直接运行
通过SeimiConfig配置,例如
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
Seimi s = new Seimi(config);
s.goRun("basic");
5.2.17.1.2.SpringBoot项目
在application.properties中配置
seimi.crawler.seimi-agent-host=xx
seimi.crawler.seimi-agent-port=xx
5.2.17.2.使用
决定哪些请求提交给SeimiAgent处理并指定SeimiAgent如何处理。这是Request级别的。
- Request.useSeimiAgent()
告诉SeimiCrawler这个请求要提交给SeimiAgent。
- Request.setSeimiAgentRenderTime(long seimiAgentRenderTime)
设置SeimiAgent的渲染时间(所有资源load完毕后,给予SeimiAgent多少时间用来执行资源中的JavaScript等脚本来渲染出最终的页面),时间单位为毫秒。
- Request.setSeimiAgentUseCookie(Boolean seimiAgentUseCookie)
告诉SeimiAgent是否要使用cookie,如果这里没有设置则使用seimiCrawler全局的cookie设置进行判断
- 其他
如果你的Crawler设置了代理,那么在这个请求转发给SeimiAgent时seimiCrawler也会自动让SeimiAgent使用这个代理。
- Demo
实际使用,大家可以参考仓库中demo
5.2.18.启动爬虫系统
5.2.18.1.SpringBoot(推荐)
application.properties 中配置
seimi.crawler.enabled=true
# 指定要发起start请求的crawler的name
seimi.crawler.names=basic,test
然后就是标准的springBoot启动了
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}
5.2.18.2.直接运行,独立启动
添加main函数,最好独立的一个启动类,就像demo工程中的那样。在main函数中,初始化Seimi这个对象,并可以通过SeimiConfig配置一些特定参数,如分布式队列要用到的Redis集群信息,如果使用seimiAgent配置相应的host信息等,当然,SeimiConfig是可选的。例如:
public class Boot {
public static void main(String[] args){
SeimiConfig config = new SeimiConfig();
// config.setSeimiAgentHost("127.0.0.1");
// config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
}
}
Seimi包含了如下启动函数,分别是:
- public void start(String... crawlerNames)指定一个或多个Crawler开始执行抓取。
- public void startAll()启动全部被加载到的Crawler。
- public void startWithHttpd(int port,String... crawlerNames)指定一个Crawler开始执行抓取,并为之启动一个指定端口的http服务,可通过/push/crawlerName推送一个抓取请求给对应的Crawler,接收参数为req,支持POST和GET。
- public void startWorkers()只初始化所有被加载到的Crawler,并监听抓取请求。这个启动函数主要用来在分布式部署的情况下启动一个或多个单纯的worker系统,这在后面关于如何进行以及支持分布式部署时会有更为细致的介绍
在工程下执行下面的命令打包并输出整个工程,
Windows下为了避免在windows控制台下日志输出乱码,请自行修改logback配置文件中控制台输出格式为
GBK,默认UTF-8。
mvn clean package&&mvn -U compile dependency:copy-dependencies -DoutputDirectory=./target/seimi/&&cp ./target/*.jar ./target/seimi/
这时在工程的target目录下会有一个叫做seimi的目录,这个目录就是我们最终编译好的可部署的工程,然后执行下面的命令进行启动,
Windows下:
java -cp .;./target/seimi/* cn.wanghaomiao.main.Boot
Linux下:
java -cp .:./target/seimi/* cn.wanghaomiao.main.Boot
以上可以自行写入脚本,目录也可以看自行情况进行调整,上面仅是针对demo工程做的一个样例。真正的部署场景,可以使用SeimiCrawler的专门打包工具maven-seimicrawler-plugin来进行打包发布。下文工程化打包部署将做详细介绍。
5.3.工程化打包部署
5.3.1.SpringBoot(推荐)
推荐使用spring boot方式来构建项目,这样能借助现有的spring boot生态扩展出很多意想不到的玩法。Spring boot项目打包参考spring boot官网的标准打包方式即可
mvn package
5.3.2.独立直接运行
上面介绍的可以方便的用来开发或是调试,当然也可以成为生产环境下一种启动方式。但是,为了便于工程化部署与分发,SeimiCrawler提供了专门的打包插件用来对SeimiCrawler工程进行打包,打好的包可以直接分发部署运行了。你只需做如下几件事即可:
pom中添加添加plugin
<plugin>
<groupId>cn.wanghaomiao</groupId>
<artifactId>maven-seimicrawler-plugin</artifactId>
<version>1.0.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>build</goal>
</goals>
</execution>
</executions>
<!--<configuration>-->
<!-- 默认target目录 -->
<!--<outputDirectory>/some/path</outputDirectory>-->
<!--</configuration>-->
</plugin>
执行mvn clean package即可,打好包目录结构如下:
.
├── bin # 相应的脚本中也有具体启动参数说明介绍,在此不再敖述
│ ├── run.bat # windows下启动脚本
│ └── run.sh # Linux下启动脚本
└── seimi
├── classes # Crawler工程业务类及相关配置文件目录
└── lib # 工程依赖包目录
接下来就可以直接用来分发与部署了。
5.4.定时调度
SeimiCrawler的定制调度完全可以直接使用spring的注解@Scheduled来实现,无需其他配置。如直接在Crawler规则文件中像如下定义即可:
@Scheduled(cron = "0/5 * * * * ?")
public void callByCron(){
logger.info("我是一个根据cron表达式执行的调度器,5秒一次");
// 可定时发送一个Request
// push(Request.build(startUrls()[0],"start").setSkipDuplicateFilter(true));
}
如果希望能定义一个独立的service类中,需保证该service类能被扫描到即可。关于@Scheduled,开发者可以自行查阅spring资料来了解它的参数细节,亦可参考SeimiCrawler在github上的Demo示例。
5.5.自动解析Bean
如果你希望定义一个Bean,SeimiCrawler可以根据你定义的规则自动将数据提取出来并填充到相应的字段上,这时你就需要这个功能了。
5.5.1.注解@Xpath
先看个例子:
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
//也可以这么写 @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
类BlogContent即是你定义的一个目标Bean,@Xpath需打在你想要注入数据的字段上,并为之配置一个XPath提取规则,不要求字段的私有与公有,亦不要求一定存在getter与setter。
5.5.2.使用
准备好Bean后,在回调函数中就可以使用Response内置函数public <T> T render(Class<T> bean)获取填充好数据的Bean对象。
5.6.拦截器
SeimiCrawler还支持给特定或所有的回调函数添加拦截器。实现一个拦截器需注意如下几点:
- 需打上@Interceptor注解
- 需实现SeimiInterceptor接口
- 所有想要被扫描生效的拦截器需放在interceptors包下,如cn.wanghaomiao.xxx.interceptors,demo工程中也有样例。
- 需自定义注解用来标记哪些函数需要被拦截或是全部拦截。
5.6.1.注解@Interceptor
这个注解用来告诉Seimi,被它标注的类可能是一个拦截器(因为作为一个真正的Seimi拦截器还要符合上述其他约定)。它有一个属性,
- everyMethod 默认false,用来告诉Seimi这个拦截器是否要对所有回调函数进行拦截。
5.6.2.接口SeimiInterceptor
直接上接口,
public interface SeimiInterceptor {
/**
* 获取目标方法应标记的注解
* @return Annotation
*/
public Class<? extends Annotation> getTargetAnnotationClass();
/**
* 当需要控制多个拦截器执行的先后顺序时可以重写这个方法
* @return 权重,权重越大越在外层,优先拦截
*/
public int getWeight();
/**
* 可以在目标方法执行之前定义一些处理逻辑
*/
public void before(Method method,Response response);
/**
* 可以在目标方法执行之后定义一些处理逻辑
*/
public void after(Method method,Response response);
}
注释中已经解释的很清楚了,这里就不在多说了。
5.6.3.拦截器样例
参考demo工程中的DemoInterceptor,gitHub地址直达
5.7.关于SeimiQueue
SeimiQueue是SeimiCrawler进行数据中转以及系统内部和系统间相互通信的唯一通道。系统默认采用的SeimiQueue是基于本地的一个线程安全的阻塞队列的一个实现。同时SeimiCrawler也支持了一个基于redis的SeimiQueue的实现--DefaultRedisQueue,当然也可以自行实现符合Seimi约定的SeimiQueue,具体使用时可以通过注解@Crawler中的queue属性来指定一个Crawler到底使用哪一种实现。
5.7.1.配置使用DefaultRedisQueue
Crawler的注解设置为@Crawler(name = "xx",queue = DefaultRedisQueue.class)
5.7.1.1.SpringBoot项目
application.properties中配置
#启动SeimiCrawler
seimi.crawler.enabled=true
seimi.crawler.names=DefRedis,test
#开启分布式队列
seimi.crawler.enable-redisson-queue=true
#自定义bloomFilter预期插入次数,不设置用默认值 ()
#seimi.crawler.bloom-filter-expected-insertions=
#自定义bloomFilter预期的错误率,0.001为1000个允许有一个判断错误的。不设置用默认值(0.001)
#seimi.crawler.bloom-filter-false-probability=
在seimi-app.xml中配置redisson,从2.0版本开始默认的分布式队列改用redisson实现,所以需要在spring的配置文件中注入redissonClient具体实现。接下来就可以正常的使用分布式队列了。
<redisson:client
id="redisson"
name="test_redisson"
>
<!--
这里的name属性和qualifier子元素不能同时使用。
id和name的属性都可以被用来作为qualifier的备选值。
-->
<!--<qualifier value="redisson3"/>-->
<redisson:single-server
idle-connection-timeout="10000"
ping-timeout="1000"
connect-timeout="10000"
timeout="3000"
retry-attempts="3"
retry-interval="1500"
reconnection-timeout="3000"
failed-attempts="3"
subscriptions-per-connection="5"
client-name="none"
address="redis://127.0.0.1:6379"
subscription-connection-minimum-idle-size="1"
subscription-connection-pool-size="50"
connection-minimum-idle-size="10"
connection-pool-size="64"
database="0"
dns-monitoring="false"
dns-monitoring-interval="5000"
/>
</redisson:client>
5.7.1.2.直接运行(非SpringBoot)
配置SeimiConfig,设置Redis集群基本信息即可,例如:
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
5.7.2.自行实现SeimiQueue
通常来讲,SeimiCrawler自带的两个实现基本足够应付绝大多数的使用场合,但是实在有应付不了的,那么您亦可自行实现SeimiQueue并配置使用。自行实现需要注意的事项有:
- 需打上@Queue注解,用来告诉Seimi这个被标记的类可能是一个SeimiQueue(成为SeimiQueue还要满足其他条件)。
- 需实现SeimiQueue接口,如下:
/**
* 定义系统队列的基本接口,可自由选择实现,只要符合规范就行。
* @author 汪浩淼 et.tw@163.com
* @since 2015/6/2.
*/
public interface SeimiQueue extends Serializable {
/**
* 阻塞式出队一个请求
* @param crawlerName --
* @return --
*/
Request bPop(String crawlerName);
/**
* 入队一个请求
* @param req 请求
* @return --
*/
boolean push(Request req);
/**
* 任务队列剩余长度
* @param crawlerName --
* @return num
*/
long len(String crawlerName);
/**
* 判断一个URL是否处理过了
* @param req --
* @return --
*/
boolean isProcessed(Request req);
/**
* 记录一个处理过的请求
* @param req --
*/
void addProcessed(Request req);
/**
* 目前总共的抓取数量
* @param crawlerName --
* @return num
*/
long totalCrawled(String crawlerName);
/**
* 清除抓取记录
* @param crawlerName --
*/
void clearRecord(String crawlerName);
}
- 所有想要被扫描生效的SeimiQueue需放在queues包下,如
cn.wanghaomiao.xxx.queues,demo工程中也有样例。 满足以上要求,写好自己的SeimiQueue后,通过注解@Crawler(name = "xx",queue = YourSelfRedisQueueImpl.class)来配置使用。
5.7.3.SeimiQueue样例
参考demo工程中的DefaultRedisQueueEG(github直达链接)
5.8.集成主流数据持久化
由于SeimiCrawler使用spring来管理bean以及进行依赖注入,所以很容易就能集成现有的主流数据持久化方案,如Mybatis,Hibernate,Paoding-jade等,在这里采用Mybatis。
5.8.1.准备工作
添加Mybatis以及数据库连接相关依赖:
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.4.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.37</version>
</dependency>
添加一个xml配置文件seimi-mybatis.xml(还记得配置文件都要以seimi打头对吧)
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="locations">
<list>
<value>classpath:**/*.properties</value>
</list>
</property>
</bean>
<bean id="mybatisDataSource" class="org.apache.commons.dbcp2.BasicDataSource">
<property name="driverClassName" value="${database.driverClassName}"/>
<property name="url" value="${database.url}"/>
<property name="username" value="${database.username}"/>
<property name="password" value="${database.password}"/>
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean" abstract="true">
<property name="configLocation" value="classpath:mybatis-config.xml"/>
</bean>
<bean id="seimiSqlSessionFactory" parent="sqlSessionFactory">
<property name="dataSource" ref="mybatisDataSource"/>
</bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="cn.wanghaomiao.dao.mybatis"/>
<property name="sqlSessionFactoryBeanName" value="seimiSqlSessionFactory"/>
</bean>
</beans>
由于demo工程中存在统一配置文件seimi.properties,所以数据库连接相关信息也通过properties注入进去,当然这里你也可以直接写进去的。properties配置如下:
database.driverClassName=com.mysql.jdbc.Driver
database.url=jdbc:mysql://127.0.0.1:3306/xiaohuo?useUnicode=true&characterEncoding=UTF8&autoReconnect=true&autoReconnectForPools=true&zeroDateTimeBehavior=convertToNull
database.username=xiaohuo
database.password=xiaohuo
工程上到目前为止已经准备好了,剩下需要你创建一个数据库和表,用来存储实验的信息,demo工程给出了表的结构,库名可以自行调整:
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
5.8.2.写一个DAO
创建一个Mybatis的DAO文件:
public interface MybatisStoreDAO {
@Insert("insert into blog (title,content,update_time) values (#{blog.title},#{blog.content},now())")
@Options(useGeneratedKeys = true, keyProperty = "blog.id")
int save(@Param("blog") BlogContent blog);
}
Mybatis的配置大家应该都了解的,就不过多说了。更多的大家可以看Demo工程或是参考Mybatis官方文档。
5.8.3.开始使用DAO
在相应的Crawler中直接注入即可,如:
@Crawler(name = "mybatis")
public class DatabaseMybatisDemo extends BaseSeimiCrawler {
@Autowired
private MybatisStoreDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s : urls) {
push(Request.build(s.toString(), DatabaseMybatisDemo::renderBean));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void renderBean(Response response) {
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={},url={}", blog, response.getUrl());
//使用神器paoding-jade存储到DB
int changeNum = storeToDbDAO.save(blog);
int blogId = blog.getId();
logger.info("store success,blogId = {},changeNum={}", blogId, changeNum);
} catch (Exception e) {
e.printStackTrace();
}
}
}
当然,如果业务很复杂的话,建议再封装一层service,然后将service注入到Crawler中。
5.9.分布式
当你的业务量与数据量达到一定程度的时候,你自然就需要水平扩展多台机器构建一个集群服务来提高处理能力,这是SeimiCrawler在设计之初就考虑的问题。所以SeimiCrawler先天就是支持分布式部署的。在上文介绍SeimiQueue相信聪明的你已经知道如何进行分布式部署了。SeimiCrawler实现分布式部署需启用DefaultRedisQueue作为默认的SeimiQueue并在每台要部署的机器上为之配置相同的redis连接信息,具体上文已有说明这里就不再啰嗦了。启用DefaultRedisQueue后,在作为worker的机器上通过new Seimi().startWorkers()初始化seimi的处理器,Seimi的worker进程就会开始监听消息队列,当主服务发出抓取请求后,整个集群就开始通过消息队列进行通信,分工合作、热火朝天的干活了。从2.0版本开始默认的分布式队列改用Redisson实现,并引入BloomFilter。
5.10.通过http服务接口操作
5.10.1.Request必填参数
如果需要像Seimicrawler发送自定义抓取请求,那么request必须要包含以下参数
url要抓取的地址crawlerName规则namecallBack回调函数
5.10.2.SpringBoot(推荐)
大家完全可以构建SpringBoot项目,自行编写spring MVC controller来处理这类需求。这里是一个简单的DEMO,你可以在这基础上做更多好玩和有意思的事情。
5.10.3.直接运行
如果不想以SpirngBoot项目形式运行的话,可以使用内建接口,SeimiCrawler可以通过选择启动函数指定一个端口开始内嵌http服务用来通过httpAPI接收抓取请求或是查看对应的Crawler抓取状态。
5.10.3.1.发送抓取请求
通过http接口发送给SeimiCrawler的Json格式的Request请求。http接口接收到抓取请求进行基本校验没有问题后就会与处理规则中产生的请求一起处理了。
5.10.3.2.接口描述
- 请求地址: http://host:port/push/${YourCrawlerName}
- 调用方式: GET/POST
- 输入参数:
| 参数名称 | 是否必选 | 参数类型 | 参数说明 |
|---|---|---|---|
| req | true | str | 内容为Request请求的json形式,单个或是Json数组 |
- 参数结构示例:
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
或是
[
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
},
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
]
结构字段说明:
| Json字段 | 是否必选 | 字段类型 | 字段说明 |
|---|---|---|---|
| url | true | str | 请求目标地址 |
| callBack | true | str | 针对对应请求结果的回调函数 |
| meta | false | map | 可选择向下文传递的一些自定义数据 |
| params | false | map | 针对当前请求可能需要的请求参数 |
| stop | false | bool | 如果为true,那么收到该请求的工作线程会停止工作 |
| maxReqCount | false | int | 如果这个请求处理异常,允许的最大重新处理次数 |
5.10.3.3.查看抓取状态
请求地址:/status/${YourCrawlerName} 即可查看一些基本的关于所指定Crawler的当前抓取状态,数据格式为Json。
6.常见问题汇总
6.1.如何设置网络代理
6.2.如何开启cookie
6.3.如何启用分布式模式
6.3.1.参考
6.3.2.特别注意
- 不同SeimiCrawler实例中的同名Crawler即会通过同一个redis进行协同工作(共享一条生产消费队列)
- 保证SeimiCrawler启动所在机器和redis是正确可联通的,一定要保证
- demo中配置了redis密码,但是如果你的redis不需要密码就不要配置密码了
- 另外很多同学遇到网络异常的情况,这种情况说明各位需要检查自己的网络情况了,SeimiCrawler用的是成熟的网络库,如果是出现了网络异常,肯定确是的网络出现了问题。包括但不限于排查,是否被目标站点针对性屏蔽、到代理是否通畅、代理是否被屏蔽、代理是否有访问外网能力、所在机器是否对外网通畅等等
6.4.如何设置复杂的起始请求
重写实现public List<Request> startRequests(),这里可以自由定义复杂的起始请求,实现了这个的情况下,public String[] startUrls()可以返回null。一个例子如:
@Crawler(name = "usecookie",useCookie = true)
public class UseCookie extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
return null;
}
@Override
public List<Request> startRequests() {
List<Request> requests = new LinkedList<>();
Request start = Request.build("https://www.oschina.net/action/user/hash_login","start");
Map<String,String> params = new HashMap<>();
params.put("email","xxx@xx.com");
params.put("pwd","xxxxxxxxxxxxxxxxxxx");
params.put("save_login","1");
params.put("verifyCode","");
start.setHttpMethod(HttpMethod.POST);
start.setParams(params);
requests.add(start);
return requests;
}
@Override
public void start(Response response) {
logger.info(response.getContent());
push(Request.build("http://www.oschina.net/home/go?page=blog","minePage"));
}
public void minePage(Response response){
JXDocument doc = response.document();
try {
logger.info("uname:{}", StringUtils.join(doc.sel("//div[@class='name']/a/text()"),""));
logger.info("httpType:{}",response.getSeimiHttpType());
} catch (XpathSyntaxErrorException e) {
logger.debug(e.getMessage(),e);
}
}
}
6.5.如何以Json体进行请求
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>2.1.2</version>
</dependency>
请确确认,使用的版本为 2.1.2或以上版本,支持在Request中设置 jsonBody属性,发起一个Json request body请求。
7.社区讨论
大家有什么问题或建议现在都可以选择通过下面的邮件列表讨论,首次发言前需先订阅并等待审核通过(主要用来屏蔽广告宣传等,给大家创造良好的讨论环境)
- 订阅:请发邮件到
seimicrawler+subscribe@googlegroups.com - 发言:请发邮件到
seimicrawler@googlegroups.com - 退订:请发邮件至
seimicrawler+unsubscribe@googlegroups.com
8.项目源码
BTW: 欢迎到github上
star^_^